A Demonstration of Self-Profiling
The separate overview of profiling as an under-appreciated feature of diagnostics support in Windows notes that although typical practice for profiling a program’s execution involves running the program concurrently with a profiling tool, a program might usefully profile itself.
The benefits of self-profiling seem plain and substantial. If the program is in real-world use, you get your diagnostics without depending on third-party tools that you have to distribute and install (and whose commercial use perhaps requires payment of a license fee), without troubling the paying customer (except perhaps to ask for permission), and without needing that the end-user has sufficient privilege to install or run a separate profiling program. Profiling the current process requires no privilege: even a low-integrity process can profile itself. Because a program that profiles itself knows its own internals, it can profile just its code that’s of special interest and it can collect separate profiles of the same code when called for different purposes. Better yet, you won’t need to distribute internal details, e.g., in symbol files, for use by an external tool: diagnostics collection need not have as its price that you make your intellectual property in your program easier to reverse-engineer.
The overview’s suggestion for “code that’s of special interest” is the program’s set of algorithms that you hope are coded for high performance. You may have instrumented the code for very close inspection during development, but how sure are you that what you decided from the instrumentation works the same way in the deployed product, which might anyway get used differently in the real world than you tested? Performance data for continued review might be nice to have, but the nature of critically high-performance routines is that you won’t have kept any instrumentation inside those routines for fear of reducing the very same performance that the routines exist to deliver.
Profiling may be your solution. It does not instrument the code, at least not by requiring any explicit change. Your current idea of the best encoding is exactly what’s built into the product as you ship it. The only change to the code is implicit: when you choose to collect diagnostics about the code, its execution gets interrupted occasionally, ever so briefly, so that the kernel makes a note for you of where the code was running. This statistical sampling of its execution is the profile, which you then examine for deductions about what happens inside the otherwise unvaried code.
That more programs don’t profile themselves, and that more Windows programmers don’t even think of it for testing a routine’s execution, is plausibly because the API functions for profiling are undocumented. As functionality, profiling is far from obscure. It certainly doesn’t need a primer and this article is not intended as one even if it does sometimes pick up the tone of one. The functions, however, are not well known. If profiling on Windows is not to remain magic that’s done by a dedicated profiling tool, then the functions for profiling need documentation, which I present separately, and a demonstration. This article presents one that puts the functions to something suggestive of real-world use and shows a programming technique by which a program’s profiling of itself can be limited just to a selected routine or routines. If you’re familiar with profiling and just want an example in code of how to do it for yourself on Windows, then skip ahead to the section headed Download.
Simple Test Case
For demonstration I take as my example what may be the smallest non-trivial algorithm that performs very differently when used slightly differently, and I use profiling to identify the cause (or at least to confirm what a suitably knowledgeable programmer might anyway infer). Let me stress again that the point to this article is not to pick over this algorithm, which is arguably too slight to support such picking, but to show that one application of self-profiling is that you could pick over any algorithm of your choice. The algorithm I've chosen really is very simple:
DWORD Test (BYTE const *Buffer, DWORD Size)
{
DWORD x = 0;
BYTE const *p;
DWORD n;
for (p = Buffer, n = Size; n != 0; p ++, n --) {
DWORD b = *p;
if (b <= 0x7F) x += b;
}
return x;
}
which I don’t doubt many would prefer to write as
DWORD Test (BYTE const *Buffer, DWORD Size)
{
DWORD x = 0;
for (DWORD n = 0; n < Size; n ++) {
if (Buffer [n] <= 0x7F) x += Buffer [n];
}
return x;
}
For the point to this simple routine (which, by the way, is adapted from a question on StackOverflow in 2012), start by giving it a large buffer of random bytes, then sort those bytes in place and re-present the buffer to the same routine. The re-run with sorted input can be an order of magnitude faster. Except for reordering, it’s the same input to the same code to get the same result but with very different performance.
Sample Experiments
The demonstration program does exactly this experiment but with some configurable options. Mostly, it’s like any test rig that anyone might cook up to establish just that the claimed difference in performance is real. The program times a large number of runs of its test routine first with randomly generated input in a 64KB buffer, and then it sorts the buffer and times a re-run of the same large number of calls to the test routine. So far, so ordinary, but timing the test routine’s execution is instrumentation only from outside. What this test rig adds is profiling to see what happens inside. Its output then shows both the times and the profiles:
J:\TEMP>profile /bucketsize:4 /source:0 /runs:100000
Interval for source 0 is 0x00009897
Times for 100000 runs are 41.824 and 6.880 seconds
Offset Unsorted Sorted
0x00000000: 0 0
0x00000004: 0 0
0x00000008: 0 0
0x0000000C: 0 0
0x00000010: 837 843
0x00000014: 2011 16
0x00000018: 1244 196
0x0000001C: 3158 695
0x00000020: 2972 0
0x00000024: 449 9
0x00000028: 0 0
0x0000002C: 0 0
========== ==========
10671 1759
and here’s another to show that there’s not much variation (if only when run on an otherwise idle computer):
J:\TEMP>profile /bucketsize:4 /source:0 /runs:100000
Interval for source 0 is 0x00009897
Times for 100000 runs are 41.871 and 6.880 seconds
Offset Unsorted Sorted
0x00000000: 0 0
0x00000004: 0 0
0x00000008: 0 0
0x0000000C: 0 0
0x00000010: 853 841
0x00000014: 2047 14
0x00000018: 1254 183
0x0000001C: 3116 707
0x00000020: 2979 0
0x00000024: 415 11
0x00000028: 0 0
0x0000002C: 0 0
========== ==========
10664 1756
The times are self-explanatory confirmations of the claim that the routine (if only as compiled for me) is much faster when given sorted input. Of course, if you build the demonstration program differently and don’t get such obviously different times for the two cases, then the demonstration’s premise doesn’t apply and there’s no immediate point to proceeding. Perhaps rebuild but with your compiler configured to optimise for space, not speed. Or use a less able compiler. Or use the build that I provide. Or replace my test routine with one of your own (which is, after all, where we’re headed).
As for the profile, i.e., the lines that begin under Offset, notice for now just how different are the numbers in each pair: profiling captures immediately that the improved performance when the test routine is given sorted input is not a uniform speed-up but happens because of very different behaviour inside. Perhaps the difference is even more plain graphically:
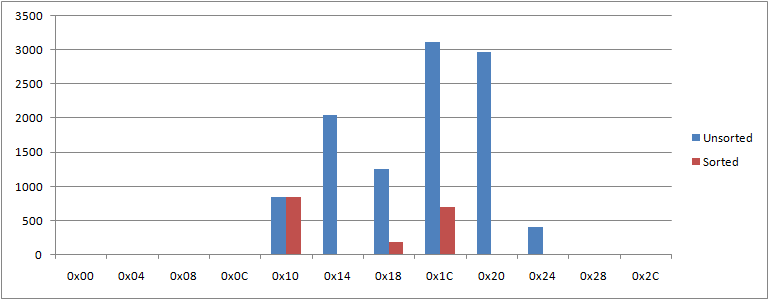
The graph—indeed, the profile itself—is a frequency distribution. Successive offsets on the horizontal axis take you further into the profiled region, not one instruction for each step, but in equally sized buckets. The numbers for each bucket, as plotted vertically, count how often a recurring hardware interrupt discovered that the address it’s to return to is in that bucket.
Division of the profiled region into buckets is both for efficiency of collection and practicality of analysis. Although the profiled region here is only very slightly larger than a very small test routine, it might in typical practice be kilobytes when studying an algorithm in real-world use or megabytes for taking in the whole of a program’s execution. Profiling gigabytes is not unknown. Just to hold execution counts for each instruction would require an impractically large output buffer—bigger than the profiled region, even—for very possibly no benefit since useful analysis at such scale would anyway aggregate the counts. Even when the profiled region is small enough that execution counts for each instruction are practical for storage and analysis, there are constraints on the act of collection which happens while handling hardware interrupts and needs to be as efficient as can be. For the experiments whose results are given above, the buckets are each 4 bytes, which is the smallest that’s allowed.
For these experiments, the /source:0 in the command line means that the profile interrupt is generated from a timer. Put very loosely, how often execution gets interrupted in any one bucket will be roughly proportional to the time the processor spends on instructions in that bucket. As confirmation, see that the total counts for the two cases have roughly the same relative proportion as do the total times:
- 10,664 / 1,756 = 6.073
- 41.871 / 6.880 = 6.086
But see also that for no one bucket do the two counts have anything like this proportion. Indeed, for the first bucket that anything is seen to have happened in, the counts are pretty much the same. From noticing such things, you might start to surmise what goes on inside the code.
Buckets and Instructions
Part of the point to self-profiling is that the profiling can feasibly be limited to just a small amount of code and be done at such resolution that you can inspect closely and not have to infer. In principle, actual deduction should be possible, and was conceivably easy once upon a time when processors executed their instructions serially. Long since then, processors have pipelines and other optimisations for reading and executing their instructions, such that even with a detailed understanding and with help from the processor itself, there’s only so far that close inspection of a sampling by time can usefully be taken. Still, the test routine is purposely small enough that presentation of its instructions for correlation with the buckets does not take us too far off-track:
| Bucket Offset | Instruction Offset | Label | Instruction |
|---|---|---|---|
| 0x04 | 0x04 |
|
xor eax,eax |
| 0x06 |
lea rcx,[Buffer] |
||
| 0x0C | 0x0D |
mov r8d,10000h |
|
| 0x10 | 0x13 |
continue: |
movzx edx,byte ptr [rcx] |
| 0x14 | 0x16 |
cmp edx,7Fh |
|
| 0x18 | 0x19 |
ja next |
|
| 0x1B |
add eax,edx |
||
| 0x1C | 0x1D |
next: |
inc rcx |
| 0x20 | 0x20 |
add r8d,0FFFFFFFFh |
|
| 0x24 | 0x24 |
jne continue |
|
| 0x26 |
rep ret |
That the counts in the profile’s first non-zero row are roughly the same for both cases is because the corresponding bucket, at offset 0x10, is the loop’s bottleneck. Apparently, as the processor moves towards the instruction in this bucket, overwhelmingly by jumping from the end of the loop, the read from separate input is enough of a barrier to optimisation that an interrupt can occur here with the same frequency no matter what the input turns out to be. It’s perhaps not necessary, but neither is it a surprise. For the rest of the loop, however, the different arrangement of input makes a world of difference. When the input is unsorted, all the rest of the loop takes substantial time. But with sorted input, the processor is somehow able to spend not just less time in the body of the loop, meaning the buckets at offsets 0x18 and 0x1C, but vanishingly little time on the mechanism of looping.
Performance Monitoring Counters (PMC)
That would be enough for many, and for years in the early history of Windows, that was pretty much all that profiling could get you. To profile by sampling meant sampling by time, and that was that.
Yet the Windows API for profiling has from as far back as version 3.51 provided for generating profile interrupts from something other than a timer. This is built in to the NtCreateProfile function as its ProfileSource argument which takes values from a KPROFILE_SOURCE enumeration. Most of the defined values anticipate generating profile interrupts from the overflow of a processor’s performance monitoring counters. Not until the introduction of 64-bit Windows, however, did Microsoft supply any HAL that actually could do that. Indeed, 32-bit Windows didn’t get such a HAL until Windows 8. Whether this is why some writers seem to think that PMC support on Windows is relatively recent, often with the suggestion that Windows is backwards for not having it earlier, I don’t know. The experiments presented here are all done on the original release of 64-bit Windows Vista to make the point that they can be.
All known HALs implement a selection of the profile sources that KPROFILE_SOURCE defines for general use, plus some—even many—that are specific to Intel and AMD processors. Of the general sources, Microsoft’s HALs since at least Windows Vista implement at most the following for processors from Intel (but beware that this sort of functionality is very much the sort of thing where it can matter that the Windows you use for testing is not in a virtual machine):
| Numeric Value | Microsoft’s Symbolic Name | Intel’s Description of Counted Event |
|---|---|---|
| 2 | ProfileTotalIssues | instructions at retirement |
| 6 | ProfileBranchInstructions | branch instructions at retirement |
| 10 | ProfileCacheMisses | last level cache misses |
| 11 | ProfileBranchMispredictions | mispredicted branch instructions at retirement |
| 19 | ProfileTotalCycles | unhalted core cycles |
For each source, whether general or vendor-specific, the processor is made to count occurrences of some event and to interrupt whenever it has seen some programmable number of them. Doing this for different events answers different questions about the profiled code’s execution. Instead of “where does my program spend most of its time?” you can learn where it suffers most from branch misprediction or cache misses.
Again, however, the sophistication of modern processors complicates close inspection. You might hope that when the profiled event occurs during the execution of some instruction and the counter overflows, the interrupt is raised at the end of the instruction such that the address it is to return to is the next instruction that the processor is to execute. This hardly ever happens, however. The interrupt is raised via the local APIC and the processor may, and even usually will, have executed more instructions before responding to the interrupt. The address that the interrupt is to return to, and which becomes the profile’s record of the event’s occurrence, will often be close to the instruction at which the event was detected, but it can be far, far away. Intel’s literature on optimisation refers to this distance between occurring and recording as skid. In practice it means you can’t expect to match execution counts to instructions precisely but can learn something useful about blocks of instructions.
For present purposes, it perhaps suffices just to pick one example of PMC profiling as might develop from hypothesising how the processor gets through the test routine’s loop so much faster when given sorted input. The nature of random input is that the check for whether any one byte is in the lower or upper half of possibilities is, well, random. Whether the conditional jump that follows will be taken or not is also random. Past experience is no guide. The processor will often have to throw away anything it might have gained from having correctly predicted which way to branch. Given sorted data, the processor can gain just by remembering which way it branched last time. If the difference in performance for the test routine’s two cases is accounted for by branch misprediction, we can expect it show if we re-run the experiment but with a profile source that is generated from branch mispredictions.
J:\TEMP>profile /bucketsize:4 /source:11 /runs:100000
Interval for source 11 is 0x00010000
Times for 100000 runs are 41.934 and 6.879 seconds
Offset Unsorted Sorted
0x00000000: 0 0
0x00000004: 0 0
0x00000008: 0 0
0x0000000C: 0 0
0x00000010: 784 2
0x00000014: 2263 2
0x00000018: 1737 1
0x0000001C: 23180 0
0x00000020: 21817 0
0x00000024: 216 0
0x00000028: 0 0
0x0000002C: 0 0
========== ==========
49997 5
It would be hard to imagine more straightforward support for the hypothesis than this (given that we can’t expect direct correlation of the execution counts with just the branch instructions). We have immediately and simply that when the test routine runs with sorted input, the processor is hardly ever seen to mispredict a branch. If that’s not enough and we want to do some analysis, we can account for the mispredictions in the unsorted case. Of the routine’s two branch instructions, the one near the end always jumps backwards until the routine’s exit. Surely the processor predicts this correctly except perhaps on the first and last times, no matter what the input. With random input, the branch after the comparison will be mispredicted roughly half the time. The default sampling interval, i.e., the programmable number of occurrences between interrupts, for counters is 0x00010000. By no coincidence, this is also the size of buffer that the test program feeds the test routine on every call and is therefore also the number of times the test routine loops. Run the test routine 100,000 times in each case, and we expect 50,000 (give or take) interrupts from branch mispredictions for unsorted input and at most a few for sorted.
Overhead
Though profiling requires no advance preparation of the profiled code, it is a sort of instrumentation by stealth. The code isn’t changed in advance and neither is the code itself changed as it runs, but what runs is not the unchanged code. Instead, its execution is repeatedly diverted by hardware interrupts that are arranged specially for profiling. These profile interrupts are extra to the usual load of hardware interrupts, e.g., from a real-time clock or to signal completion of I/O. If the profile interval is left at its default, this extra load is barely noticeable. But it is measurable and it can be made severe if the interval is reduced far enough.
For each profile source that the HAL supports, there is a default interval, a minimum and a maximum. The minimum interval when the profile source is a timer is 0x04C5. This is in the usual unit of low-level Windows timing, i.e., 100 nanoseconds. It’s a bit more than a hundred microseconds. (It makes more sense as a reciprocal, being 8,192 interrupts per second.) That makes it frequent but not ridiculously so. Even this minimum interval is still two orders of magnitude larger than what might be hoped is typical for the time taken to service each interrupt. That allows plenty of opportunity for the profiled code to run as normal. But rerun the experiment, with the interval reduced to its minimum, and you will see that profiling slows everything by one or two percent.
J:\TEMP>profile /bucketsize:4 /interval:0x04c5 /source:0 /runs:100000
Interval for source 0 is 0x00009897
Interval for source 0 changed to 0x000004C5
Times for 100000 runs are 42.495 and 7.004 seconds
Offset Unsorted Sorted
0x00000000: 0 0
0x00000004: 1 1
0x00000008: 0 0
0x0000000C: 0 0
0x00000010: 27461 27590
0x00000014: 66238 409
0x00000018: 40129 6172
0x0000001C: 102608 22629
0x00000020: 95943 11
0x00000024: 14746 353
0x00000028: 0 0
0x0000002C: 0 0
========== ==========
347126 57165
Because, inevitably, programmers will think to improve their samples by increasing the sampling rate, a few words of caution seem in order. Broadly speaking, there are two considerations: first, the effect on the profiled program and the integrity of the sample; second, the effect on everything else. Call me a cynic, but in my experience programmers tend to think first about the first and even when they think second about the second they still think the first is more important. So, let’s start there.
Though the minimum interval when the profile source is a timer typically has no great performance impact, being still much longer than the time taken for each interrupt, this is certainly not true of the minimum interval for some counters. All known HALs allow 0x00001000 as the minimum interval for all counters. This means that whatever event the counter counts, every 4096 such events cause an interrupt. The impact depends on the event. If the event is something that occurs often, then so will the interrupt. Intel’s processors give a dramatic example because they can generate interrupts from a counter of CPU cycles. The magic number for the /source switch in my demonstration program is 19. The following graph shows how the times for the demonstration’s two cases increase as the profile interval for this source is repeatedly halved:
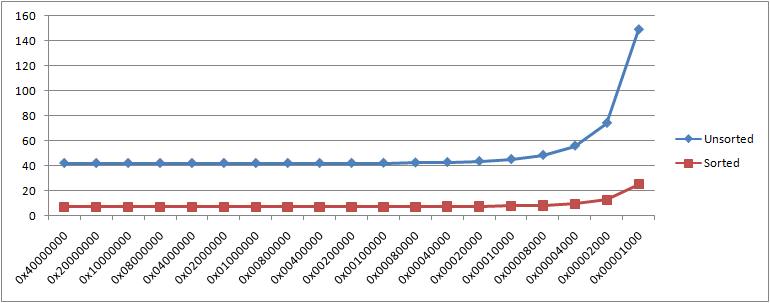
Setting the interval between interrupts to be mere thousands of core cycles has as its result that the processor spends as much time, or more, on the interrupts as on the ordinary code. That is, clearly, the extreme case. Still, if you’re thinking that a quick way to increase the execution counts in a profile is to increase the sampling frequency, then even for your own purposes think again.
Download
For distribution, the demonstration described above—of how a program may profile the execution of selected routines within itself—is compressed into zip files both with and without source code:
- x86 executable (6KB compressed from 12KB);
- x64 executable (6KB compressed from 12KB);
- source code (18KB compressed from 49KB).
The executables are built for execution on Windows versions from as long ago as Windows Vista, for easy demonstration that the implementation of processor performance monitoring counters as profile sources is no new thing—well, not for 64-bit Windows.
Execution
Run with the /? or /help command-line switch to get a summary of the command-line syntax.
You will get better results on 64-bit Windows if you run the x64 build. Indeed, a 32-bit build that targets versions from before Windows 7 will almost certainly complain if run on a newer 64-bit Windows. This is because I’ve taken the opportunity to slip in a demonstration of the Wow64 quirk that I document for NtCreateProfile.
Source Code
The source code is all in one directory so that the demonstration is as self-contained yet adaptable as I think it can be.
The substance of the program is in three source files. Were profiling not involved, there might be just a MAIN.CPP and a TEST.CPP. The latter has the replaceable code whose execution is to be timed. The former does command-line parsing and directs the repeated execution of the test code to build a good sample. To add profiling, MAIN.CPP is changed to supervise the sampling, by calling code in PROFILE.CPP, and to present the profile. The code in TEST.CPP knows nothing of PROFILE.CPP but also requires a small change: the code that is to be profiled must be placed in a specially named section, defined in PROFSEG.H, so that the code in PROFILE.CPP can know where the profiled area starts and ends.
Section allocation may seem an encumbrance. Many user-mode programmers go their whole working lives without thinking of sections. It is appropriate, however, if we look ahead to profiling the execution of code that has real-world interest. The point to such interest is likely that the code is developed for high performance, perhaps with other code which would all sensibly be put in its own (page-aligned) section to keep it together at run-time with less risk of delays from paging I/O—and, indeed, from such things as cache misses that you might want to profile for.
Building
As is natural for a low-level Windows programmer—in my opinion, anyway—all the source code is written to be built with Microsoft’s compiler, linker and related tools, and with the headers and import libraries such as Microsoft supplies in the Software Development Kit (SDK). Try building it with tools from someone else if you want, but you’re on your own as far as I can be concerned.
Perhaps less natural for user-mode programming is that the makefile is written for building with the Windows Driver Kit (WDK), specifically the WDK for Windows 7. This is the last that supports earlier Windows versions and the last that is self-standing in the sense of having its own installation of Microsoft’s compiler, etc. It also has the merit of supplying an import library for MSVCRT.DLL that does not tie the built executables to a particular version of Visual Studio. For this particular project, the WDK also helps by supplying an import library for NTDLL.DLL, which allows that the demonstration is not cluttered by mucking around with declarations of function pointers and calls to GetProcAddress for using the several undocumented functions that the demonstration relies on.
To build the executables, open one of the WDK’s build environments, change to the directory that contains the source files, and run the WDK’s BUILD tool. Try porting it to an Integrated Development Environment (IDE) such as Visual Studio if you want. I would even be interested in your experience if what you get for your troubles is in any sense superior.
Alternatively, ignore the makefile and the IDE: just compile the source files from the command line however you like, and link. The only notable extra that I expect, even from an old Visual Studio and SDK, is the NTDLL.LIB import library. You can get this, of course, from any old WDK. If you encounter a problem from rolling your own build via the command line, then please write to me with details of what combination of tools you used and what errors or warnings they produced, and I will do what I can to accommodate.
Reading
An indirect merit of using the WDK from Windows 7 comes from human preparation of makefiles. Among the many reasons that I have never seen Visual Studio as being worth my time to grapple with, even now that it explicitly supports kernel-mode driver programming, is that its automated generation of makefiles hides the build details. Though the goal is surely to help the programmer, it can frustrate the reviewer as a side-effect. Makefiles provide naturally for commenting, i.e., for describing what’s in the various source files and why they are built in any particular way. I strongly recommend that you start your reading with the SOURCES file—which is essentially a makefile inclusion.